Relatively unknown fact about how browsers may cache your assets without you explicitly instructing them to.
Ever found yourself in a situation when your assets are being cached by browsers without you explicitly instructing them to? Read on this article is for you then.
Normally there are 3 scenarios possible when working with browser caches and your static assets.
- First is when you instruct the browser to cache your assets for a certain amount of time via cache-control or Expires headers in response from your server. Browser keeps serving requests for those assets from its cache without hitting the network.
- Second is when you wish to use browser cache for a certain amount of time as mentioned above but when that time expires you wish to re-validate the copy of the resource in browser cache with your origin server. This happens with etags headers and it's fallback last Modified headers.
- The third is when you do not wish to cache your assets at all at any point in time and you wish to hit the network for all your requests. This happens with
cache-control:no-storeheader.
We were recently working with an application that was being served from Aws's CDN service Cloudfront at work and while performing regular deployments I noticed that the clients at times did not receive newer versions of files as intended. We use dockers for deployment and we checked if all frontend dockers had the latest versions which it had. The Cloudfront cache invalidation was also being perfectly invalidated and we tested it by CURLing one of the static assets. So as all seemed good at the backend, it was time to visit the client and open dev tools to see what was going on here.
When inspecting the network pane for requests made by the browser for the stale resource in question I found a strange behavior. After fetching it once the browser was fetching the file from its cache without even validating with the server if the copy it had was fresh. This was not what we expected the browser to behave as we did not instruct it in any way to cache the response by providing the requested headers it needs from the server. Below is the screenshot showing the first request on right and the subsequent request served from the cache on left.
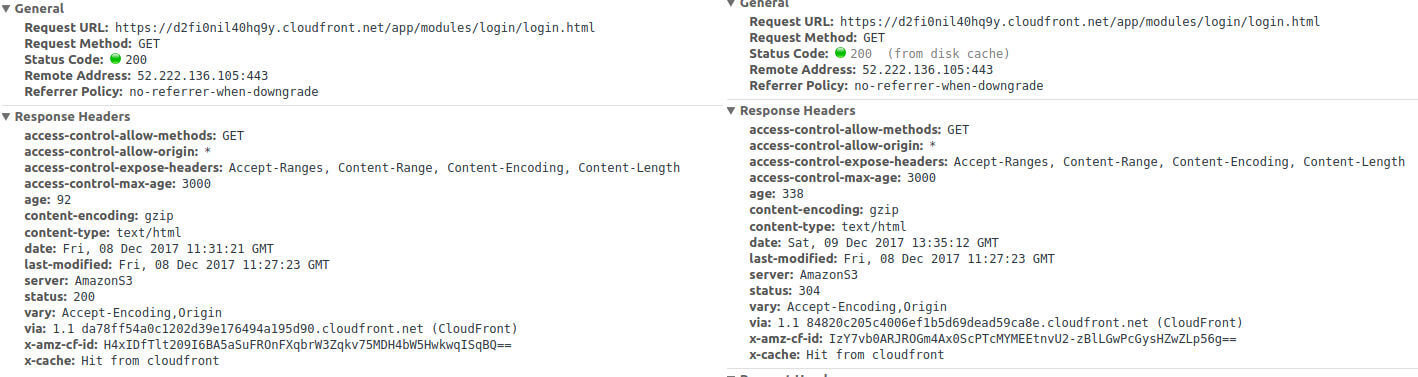
As visible in the image above on the left is the request with 200 OK status code and I made that request using the no-cache option on from devtools to hit my origin server. It fetches the original file bypassing the cache as expected. Notice the Last-modified header in its response.
On the right is the request which I made immediately after few seconds of the previous request for the same resource and chrome weirdly fetches it from disk cache without hitting the network at all.
This can prove disastrous for us in production as we are not guaranteed that users will see an updated version of our application once we perform a deployment. A horror story plot if you are publishing a critical hotfix!
I then decided to re-read about how the browser caches assets and the headers required in search of some wisdom as I felt there was something that was being sent from our origin servers which were instructing the browser to cache assets. But I did could point it out (turns out I should have read the w3c spec for caching more keenly).
Then after meddling for about an hour on Stackoverflow, it struck! I read about something called Heuristic Expiration mentioned in the HTTP Caching Spec and that was it. It was the reason why Chrome was magically caching my assets without me instructing it to do so. Basically what the spec says that if your servers do not explicitly tell the browser (by not setting appropriate response headers) when a resource expires the browser calculates a certain time based on a heuristic algorithm and decides to serve a subsequent request for that resource from its cache until that time expires.
Let's revisit the example of my two requests above it better understand it. The first request on right has a response header Last-modified with value of 08 Dec 2017 11:27:23. The request on right has date header with the value of 09 Dec 2017 13:35:12. The heuristic also that chrome uses to calculate the time is (date-modified - date) * .10
Using the above formula if we substitute the values we get a time duration of 156.8 minutes. This means that for the next 156 minutes any request that the browser receives for that request will instantly serve it from the cache. On the 157th minute browser will go to the server to fetch the resource again as the copy of the resource it has in its cache is stale now.
Point worth noting is that browsers will apply generally apply heuristic caching only if there is Last-modified header from your server (i have not verified this fact practically). If you are concerned about the formula different browsers use according to various forums and SO threads such as this most of the popular browsers work on the same formula that we saw above. In that SO question there are links to actual browser source code where you can verify this fact.
One another fact that about Date header that I initially didn't understand is that Date header stands for the date and time when the resource was fetched. It does not mean that it will necessarily have the value of date time when you request a resource from your browser. In my case, as I used a CDN the date value in request/response is the date-time when Cloudfront requested my origin (in my case S3). Hence once Cloudfront caches a resource all my next subsequent requests will hit CloudFront cache and all those requests will have the same Date header value as Cloudfront is not making any requests to my origin.
Conclusion
To avoid forcing browsers to invoke heuristic freshness value calculation, it is recommended you set up your origin servers to have either Cache-control:max-age value-in-seconds or Expires value-in-seconds header so that browsers know exactly when they should consider a resource stale and hit the network. If you are working with S3 and using Cloudfront like me, you will need to add required headers as meta-data to your S3 objects a guide to which can be found here.
Still not working for you? Trouble understanding or implementing caching? Hit me up in comments or on twitter(@vinayn_b). Thanks for reading.